As explained in more detail in my my last blog post, Rackspace is providing hosting for Debian Code Search. For those of you who don’t know, Rackspace is a cloud company that provides (among other services) a public cloud based on OpenStack. That means you can easily (and programmatically, if you want) bring up virtual servers, block storage volumes, configure the network between them, etc.
As part of my initial performance experiments, I was running debmirror to clone a full Debian source mirror, and I noticed this took about one hour. Given that the peak network and storage write rates I have observed in my benchmarks are much higher, I wondered why it took so long. About 43 GB (that’s how big the Debian sid sources are) in 60 minutes means ≈ 12 MB/s download rate, which is a bit more than a sustained 100 MBit/s connection. Luckily, at least the Rackspace servers I looked at are connected with 1 GBit/s to the internet, so more should be possible. Note that these are the old Rackspace servers. There is a new generation of servers, which I have not yet tried, that apparently offer even higher performance.
After a brief look at the debmirror source code, I concluded that it can only use a single mirror and downloads files sequentially. There is some obvious potential for improvement here, and the fact that I could come up with a proof of concept written in Go to determine the files to download in a couple of minutes encouraged me to spend my saturday on this “problem” :-).
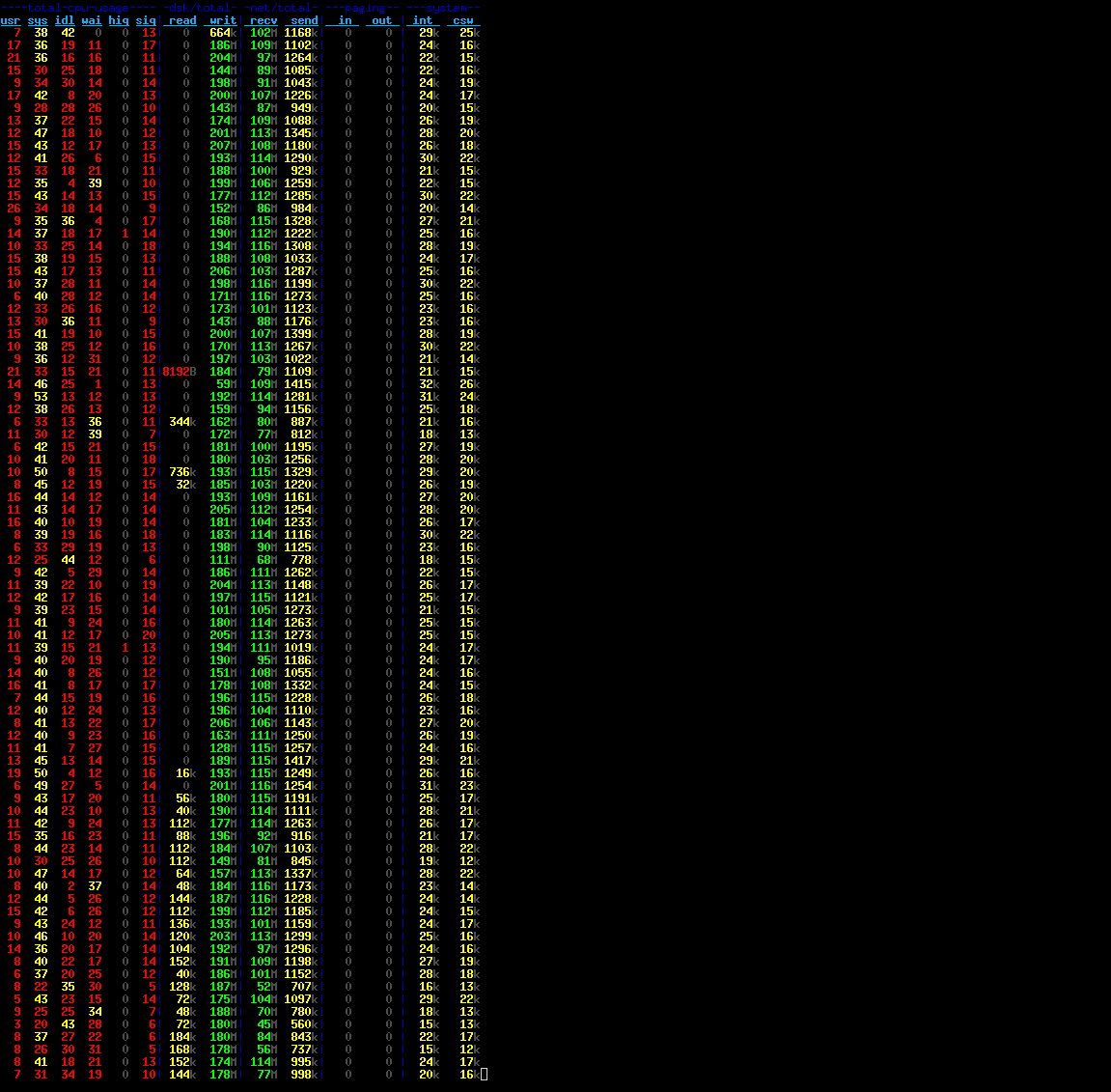
About 7 hours later, my prototype had gone through various iterations and the code could sustain about 115 MB/s incoming bandwidth for most of the time. Here is a screenshot of dstat measuring the performance:
Another 3 hours later, the most obvious bugs were weeded out and the code successfully cloned an entire mirror for the first time. I verified the correctness by running debmirror afterwards, and no files were downloaded that had not actually arrived on the mirror in the meantime.
.edu that I tried was
really slow — most of them providing something like 2-4 MB/s.
With the latest iteration of the code, I can clone an entire Debian source mirror with ≈ 43 GB of data in about 11.5 minutes, which corresponds to a ≈ 63 MB/s download rate:
GOMAXPROCS=20 ./dcs-debmirror -num_workers=20 68,24s user 384,90s system 66% cpu 11:25,97 total
It should be noted that the download rate is very low in the first couple of seconds since the sources.gz file is downloaded from a single mirror, then unpacked and analyzed.
The peak download rate is about 115 MB/s (= 920 MBit/s) which is reasonably close at what you can achieve with a Gigabit link, I think. If the entire uplink was available to me at all time, the Rackspace hardware would be able to saturate that easily, both in terms of reading from the network and in terms of writing to block storage. I tested this on an SSD volume, but I see about 113 MB/s throughput with the internal hard disk, so I think that should work, too.
There is another dstat screenshot of the final version (writing to disk).
Perhaps even more interesting to some readers is the time for an incremental update:
GOMAXPROCS=20 ./dcs-debmirror -tcp_conns=20 2013/10/13 11:09:55 Downloading 307 files (447 MB total) … 2013/10/13 11:10:04 All 307 files downloaded in 9.105605931s. Download rate is 49.186567 MB/s 4,91s user 3,99s system 67% cpu 13,205 total
The wall clock time is higher than the time reported by the code because the code does not count the time for downloading and parsing the sources.gz file.
The entire program is about 400 lines (not SLOC) of Go code. It’s part of the Debian Code Search source. If you’re interested, you can read dcs-debmirror.go in your browser.
The outcome of this experiment is that I now know (and have shown!) that there are significantly more efficient ways of cloning a Debian mirror than what debmirror does. Furthermore, I have a good grasp on what kind of performance the Rackspace cloud offers and I am fairly happy with the numbers :-).
My code is useful to me in context of Debian Code Search, but unless you need a sid-only source-only mirror, it will not be useful to you directly. Of course you can take the ideas that I implemented and implement them elsewhere — personally, I don’t plan to do that.
If you have hardware, bandwidth and a use-case for 10 GBit/s+ mirroring, I’d like to hear about it! :-)
{kind=link}