
Earlier today, I uploaded debhelper version 10.5.1 to unstable. The following are some highlights compared to version 10.2.5:
- debhelper now supports the "meson+ninja" build system. Kudos to Michael Biebl.
- Better cross building support in the "makefile" build system (PKG_CONFIG is set to the multi-arched version of pkg-config). Kudos to Helmut Grohne.
- New dh_missing helper to take over dh_install --list-missing/--fail-missing while being able to see files installed from other helpers. Kudos to Michael Stapelberg.
- dh_installman now logs what files it has installed so the new dh_missing helper can "see" them as installed.
- Improve documentation (e.g. compare and contrast the dh_link config file with ln(1) to assist people who are familiar with ln(1))
- Avoid triggering a race-condition with libtool by ensuring that dh_auto_install run make with -j1 when libtool is detected (see Debian bug #861627)
- Optimizations and parallel processing (more on this later)
There are also some changes to the upcoming compat 11
- Use "/run" as "run state dir" for autoconf
- dh_installman will now guess the language of a manpage from the path name before using the extension.
Updating Britney often makes our life easier. Like:
- smooth-updates (winter 2011)
- Adam's accidental upgrade of the original auto-hinter[1] (winter 2012)
- A non-leaking installability tester (winter 2013)
- Fix non-determinism of easy-hinted smooth updatable packages (summer 2014)
- Support for non-hinted multi-item migrations (autumn 2015)
Concretely, transitions have become a lot easier. When I joined the release team in the summer 2011, about the worst thing that could happen was discovering that two transitions had become entangled. You would have to wait for everything to be ready to migrate at the same time and then you usually also had to tell Britney what had to migrate together.
Today, Britney will often (but not always) de-tangle the transitions on her own and very often figure out how to migrate packages without help. The latter is in fact very visible if you know where to look. Behold, the number of manual "easy" and "hint"-hints by RT members per year[2]:
Year | Total | easy | hint -----+-------+------+----- 2005 | 53 | 30 | 23 2006 | 146 | 74 | 72 2007 | 70 | 40 | 30 2008 | 113 | 68 | 45 2009 | 229 | 171 | 58 2010 | 252 | 159 | 93 2011 | 255 | 118 | 137 2012 | 29 | 21 | 8 2013 | 36 | 30 | 6 2014 | 20 | 20 | 0 2015 | 25 | 17 | 8 2016 | 16 | 11 | 5 2017 | 1 | 1 | 0
As can be seen, the number of manual hints drop by factor of ~8.8 between 2011 and 2012. Now, I have not actually done a proper statistical test of the data, but I have a hunch that drop was "significant" (see also [3] for a very short data discussion).
In conclusion: Smooth-updates (which was enabled late in 2011) have been a tremendous success. :)
--
[1] A very surprising side-effect of that commit was that the ("original") auto-hinter could now solve a complicated haskell transition. Turns out that it works a lot better, when you give correct information! :)
[2] As extracted by the following script and then manually massaged into an ASCII table. Tweak the in-line regex to see different hints.
respighi.d.o$ cd "/home/release/britney/hints" && perl -E '
my (%years, %hints);
while(<>) {
chomp;
if (m/^\#\s*(\d{4})(?:-?\d{2}-?\d{2});/ or m/^\#\s*(?:\d+-\d+-\d+\s*[;:]?\s*)?done\s*[;:]?\s*(\d{4})(?:-?\d{2}-?\d{2})/) {
$year = $1; next;
}
if (m/^((?:easy|hint) .*)/) {
my $hint = $1; $years{$year}++ if defined($year) and not $hints{$hint}++;
next;
}
if (m/^\s*$/) { $year = undef; next; }
};
for my $year (sort(keys(%years))) {
my $count = $years{$year};
print "$year: $count\n"
}' * OLD/jessie/* OLD/wheezy/* OLD/Lenny/* OLD/*
[3] I should probably mention for good measure that extraction is ignoring all hints where it cannot figure out what year it was from or if it is a duplicate. Notable it is omitting about 100 easy/hint-hints from "OLD/Lenny" (compared to a grep -c), which I think accounts for the low numbers from 2007 (among other).
Furthermore, hints files are not rotated based on year or age, nor am I sure we still have all complete hints files from all members.
The soft freeze has been on going for almost a month now and the full stretch freeze will start tomorrow night (UTC). It has definitely been visible in the number of unblock requests that we have received so far. Fortunately, we are no where near the rate of the jessie freeze. At the moment, all unblock requests are waiting for the submitter (either for a clarification or an upload).
Looking at stretch at a glance (items are in no particular order):
- Secure boot support is progressing too slowly.
- The openssl transition is still on-going and badly needs closure.
- The MySQL to MariaDB transition is done.
- The gcc-5 removal almost complete - missing only 2 packages.
- About 150 RC bugs (in key packages) need to be handled
- We are missing a stretch-backport suite so DSA can start their upgrade tests
- The release checklist have a few items that could be completed now.
Secure boot support
Currently, we are blocked on two items:
- We do not have signing done yet for the boot packages (not even manual signing).
- Our shim is not yet signed, so no hardware would be trusting our boot chain out of the box.
Where can you help with the release?
At the moment, the best you can do is to:
- Test (packages, upgrades, etc.) and report bugs
- File bugs against release-notes for issues that should be documented
- Fix RC bugs (please see the next section)
Release Critical Bug report
The UDD bugs interface currently knows about the following release critical bugs:
In Total:1148(Including193bugs affectingkey packages)
Affecting stretch:294(key packages:158) That's the number we need to get down to zero before the release. They can be split in two big categories:
Affecting stretch and unstable:232(key packages:134) Those need someone to find a fix, or to finish the work to upload a fix to unstable:
- 30bugs are tagged 'patch'. (key packages:21) Please help by reviewing the patches, and (if you are a DD) by uploading them.
- 17bugs are marked as done, but still affect unstable. (key packages:5) This can happen due to missing builds on some architectures, for example. Help investigate!
- 185bugs are neither tagged patch, nor marked done. (key packages:108) Help make a first step towards resolution!
Affecting stretch only:62(key packages:24) Those are already fixed in unstable, but the fix still needs to migrate to stretch. You can help by submitting unblock requests for fixed packages, by investigating why packages do not migrate, or by reviewing submitted unblock requests.
As of today, britney now fetches reports from piuparts.debian.org and uses it as a part of her evaluation for package migration. As with her RC bug check, we are only preventing (known) regressions from migrating.
The messages (subject to change) look something like:
- Piuparts tested OK
- Rejected due to piuparts regression
- Ignoring piuparts failure (Not a regression)
- Cannot be tested by piuparts (not a blocker)
If you want to do machine parsing of the Britney excuses, we also provide an excuses.yaml. In there, you are looking for "excuses[X].policy_info.piuparts.test-results", which will be one of:
- pass
- regression
- failed
- cannot-be-tested
Enjoy. :)
Yesterday, I just uploaded apt-file 3.1.2 into unstable, which comes with a few things I would like to highlight.
- We fixed an issue where apt-file would not show top-level files in source packages. (bug#676642). Thanks to Paul Wise for the proposed solution.
- Paul Wise also fixed a bug where apt-file list -I dsc <source-pkg> would fail to list all files in the source package if said file was also in other packages.
- We added --filter-suites / --filter-origins options that can be used to narrow the search space. Example: apt-file search --filter-suites unstable lintian/checks/
You can also set defaults in the config file - if you want to always search in unstable, simply do:
# echo 'apt-file::Search-Filter::Suite "unstable";' >> /etc/apt/apt-file.conf
For the suite filter, either a code name ("sid") or a suite name ("unstable") will work. Please note that the filters are case-sensitive - suites/code names generally use all lowercase, whereas origins appear to use title-case (i.e. "unstable" vs. "Debian").
It is the first of October and that means the transition freeze is roughly one month away (Nov 5th 2016). In other words, this is the "final boarding call for transitions".
Other milestone dates:
- If you want new packages into Stretch, you have about 3 months (Jan 5th 2017). This includes auto removed packages.
- Automatic updates of existing packages stop in 4 months (Feb 5th 2017)
We have been making a lot of minor changes to lintian.d.o and the underlying report framework. Most of them were hardly noticeable to the naked. In fact, I probably would not have spotted any of them, if I had not been involved in writing them. Nonetheless, I felt like sharing them, so here goes. :)
User "visible" changes:
- The generated reports are now in HTML5 rather than XHTML. [commit:9652c2e]
- Add "alt" texts to graphs for [commit:83434ec]
- Wrap front page index in a <nav> and reword link text so they can stand alone [commit:13993c8]
- Fix index of maintainer names, so characters outside [A-Z] always go at the end plus add a link directly to that section. [commit:70a24ed, commit:94eb258]
- Put the "banner" links in a <nav> [commit:baa77fc]
- Always create an index of packages on the individual maintainer pages [commit:124f9a8]
- Wrap the above-mentioned indices in a <nav> tag [commit:2ecea9b]
- Make the links in these indices self-contained [commit:bfc5292, commit:1043d4d]
- Fix mojibake in maintainer names [commit:e907388]
In case you were wondering, the section title is partly a pun as half of these changes were intended to assist visually impaired users. They were triggered by me running into Sam Hartmann at DebConf16, where I asked him about how easy Debian's websites were for blind people. Allegedly, we are generally doing quite good in his opinion (with one exception, for which Sam filed Bug#830213), which was a positive surprise for me.
On a related note: Thanks Luke Faraone and Asheesh Laroia for getting helping me started on these changes. :)
Reporting framework / "Internal" changes:
- Harness supports a "−−no−generate−reports" to make report generation optional. [commit:21fab0b]
- Reduced memory requirements for reports generation by ~15% [commit:534d169]
- Refactored reporting frontends to share the same bootstrap code as lintian/lintian-info ("dplint") [commit:7d9a7d1, commit:97cf104, plus a bunch of refactoring leading up to those commits]
- Add "sub-resource integrity" fields in <link> tags [commit:27a367d]
- Add a "Content-Security-Policy" (via a <meta http-equiv>-tag) [commit:b022a39, commit:30bdc90]
- Support mirrors using "Packages.xz" files and without SHA1 fields [commit:d9cf314, commit:cb05f1d]
- Shuffle the lintian backlog to randomize the workload [commit:9b8873f]
- Stop lintian when the dead-line/run-time limit is exceeded [commit:7032be5, commit:7b3190d, commit:62532f8]
With the last change + the "−−no−generate−reports" option, we were able to schedule lintian more frequently. Originally, lintian only ran once a day. With the "−−no−generate−reports", we added a second run and with the last changes, we bumped it to 4 times a day. Unsurprisingly, it means that we are now reprocessing the archive a lot faster than previously.
All of the above is basically the all the note-worthy changes on the Lintian reporting framework since the Partial rewrite of lintian’s reporting setup (~1½ years ago).
Today, debhelper 10 was uploaded to unstable and is coming to a mirror near you "really soon now". The actual changes between version "9.20160814" and version "10" are rather modest. However, it does mark the completion of debhelper compat 10, which has been under way since early 2012.
Some highlights from compat 10 include:
- The dh sequence in compat 10 automatically regenerate autotools files via dh_autoreconf
- The dh sequence in compat 10 includes the dh-systemd debhelper utilities
- dh sequencer based packages now defaults to building in parallel (i.e. "--parallel" is default in compat 10)
- dh_installdeb now properly shell-escapes maintscript arguments.
For the full list of changes in compat 10, please review the contents of the debhelper(7) manpage. Beyond that, you may also want to upgrade your lintian to 2.5.47 as it is the first version that knows that compat 10 is stable.
Thanks to Lucas Nussbaum, we now have a UDD script to filter/select key packages. Some example use cases:
Which key packages used compat 4?
# Data file compat-4-packages (one *source* package per line) $ curl --silent --data-binary @compat-4-packages \ https://udd.debian.org/cgi-bin/select-key-packages.cgi alsamixergui apg [...] sgml-base wwwconfig-common
Also useful for things like bug#830997, which was my excuse for requesting this. :)
Is package foo a key package (yet)?
$ is-key-pkg() {
RES=$(echo "$1" | curl --silent --data-binary @- \
https://udd.debian.org/cgi-bin/select-key-packages.cgi)
if [ "$RES" ]; then
echo yes
else
echo no
fi
}
$ is-key-pkg bash
yes
$ is-key-pkg mscgen
no
$ is-key-pkg NotAPackage
no
Above shell snippets might need tweaking for better error handling, etc.
Once again, thanks to Lucas for the server-side UDD script. :)
Today, we have completed our first Britney run with mips64el enabled in testing. :)
At the current time, the set of packages in mips64el are not very connected (and you probably cannot even install build-essential yet[1]). Hopefully this will change over the next few days. For now, Britney does not enforce installability of packages on mips64el in general, so do not expect the architecture to be stable at the moment.
Cheat sheet for package maintainers:
- Issues with builds (only) on mips64el are not blockers for testing migration (nor RC yet).
- Such bugs should be filed as "important" for now (unless they also affect a release architecture, in which case you should still make it an RC bug)
- Your package be an older version on mips64el compared to other architectures.
- Britney may decide to break your package on mips64el if it means something else can migrate on a release architecture.
We will slowly remove these special cases for mips64el as it matures in testing.
[1] Update on this: mips64el currently does not have a libc library yet, so build-essential is definitely not installable at the moment. It will hopefully migrate very soon.
Debian packages can run arbitrary code via "maintainer scripts" (sometimes shortened into "maintscripts") during installation/removal etc. While they certainly have their use cases, their failure modes causes "exciting" bugs like "fails to install" or the dreaded "fails to remove".
They also have other undesirable effects such as:
- Bugs in/Updates to auto-generated snippets require a rebuild of all packages (not to mention the obvious code-duplication in all packages).
- In case of circular dependencies[1] all having "postinst" scripts, dpkg will have to guess which package to configure first.
- They require forking a shell at least once for each maintscript.
- They complicate the implementations of e.g. detached chroot creation.
Accordingly, I think we should aim for a more declarative packaging style. To help facilitate this, I have implemented 3 tracking tags in Lintian.
- no-ctrl-scripts in 2.5.44
- ctrl-script in 2.5.44
- debhelper-autoscript-in-maintainer-scripts in 2.5.45
With these, we were able to learn that 73.5% of all packages do not have any of these scripts. But I can now also produce a list of helpers that insert the most maintainer script snippets. The current top 15 is:
- "dhpython" with 3775 instances
- This is an umbrella for all helpers using dh-python's python module, see #827774.
- dh_installmenu with 1861 instances
- This will presumably drop as menu files should be replaced with desktop files.
- dh_makeshlibs with 1396 remaining instances
- This should be in rapid decline since we decided to replace its scripts with a dpkg trigger. Unfortunately, it can take quite a while until all of them have been rebuilt with a new version of debhelper
- dh_installinit with 1224 instances
- dh_python2 with 1168 instances
- dh_installdebconf with 772 instances
- dh_installdeb with 754 instances
- These are the dpkg-maintscript-helper snippets for "rm_conffile", "mv_conffile" etc. Hopefully in the near future, dpkg will support these directly.
- dh_systemd_enable with 447 instances
- dh_installemacsen with 179 instances
- dh_icons with 165 instances
- dh_installtex with 137 instances
- dh_apache2 with 117 instances
- dh_installudev with 98 instances
- dh_installxfonts with 87 instances
- dh_systemd_start with 79 instances
With this list, it seems to me that some obvious focus areas would be:
- Replacing the python scripts (I presume it is the byte-code handling, but I have not looked at this at all)
- Migrating away from menu files
- Support enabling + starting/stopping/restarting a service declaratively.
- This might have a "hidden" requirement on declaratively creating service users if we want these packages to become truly "maintscript-less".
Eventually we will also have to dig through all the "manual" maintainer scripts. But I think we got plenty to start with. :)
[1] For some, circular dependencies in itself is an issue. I can certainly appreciate them as being suboptimal, but most of the issues we have are probably caused by insufficient tooling rather than a theoretical issue (that is, if we remove all postinst scripts).
I just submitted another patch series to improve Britney for review. If accepted, they will probably be merged into master within 2 weeks. The changes this time are probably most exciting for people that run/maintain Britney. Key highlights include:
- Britney will be able to use a regular mirror (without partial suites) as data source
- Previously you would have to decompress and merge the Packages/Sources for each component.
- Partial suite support is still not added, but I hope to add it eventually. I know it is feature used by at least Ubuntu.
- This change implies renaming some input files around (Dates, Urgency and BugsV files) as Britney expected these next to the Packages files.
- More machine parsable facts added to "excuses.yaml". It will cover almost all excuses currently in use.
- Britney will support two use cases for "faux packages" natively.
- I hope to use this to eliminate our need to "injecting" fake packages into Britney's data source.
I would like to dwell a moment on the "faux packages". We have had a helper script generate and inject fake packages into the list of packages (called "faux packages"). They generally serve two purposes, which Britney will support:
- Whitelist of fake packages to satisfy dependencies of other packages.
- These are generally stand-in for non-free machine configuration packages, where the end-user system would also fetch packages from the vendor's repository.
- Packages relying on "faux packages" are generally not in "main" as Debian's main component is required to be self-contained.
- These are (still) be called "faux packages" in/after the patch series
- Ensuring that certain packages are present and installable in testing.
- We have a lot of d-i related packages here to avoid accidental breakage of d-i.
- These are now referred to as a "constraint" (assuming there is no bike-shedding over the name).
Since Britney will now distinguish between these two use cases, I also make Britney enforce the second use case slightly better. Mind you, it can still be overruled by force-hints and BREAK_ARCHES, so there still enough rope to hang yourself.
The other exciting part of this patch set (for me, at least) is that Britney will hopefully become simpler to deploy. No doubt there are still some missing features and paper cuts left, but I suspect we are not far from a:
- Fill out a template config file pointing Britney to your mirror
- Run britney -c britney.conf
- Make your archive kit update your target suite based on Britney's output.
- Put step 2+3 in crontab/jenkins/task scheduler of choice
- Profit
There will certainly be some features that requires extra steps. An example is the "anti rc-bugs regression" feature, which requires you to feed Britney with the list of RC bugs for your source and target suite. But even without, Britney would still protect your target suite from most installability issues.
About 10 months ago, we enabled an auto-decrufter in dak. Then after 3 months it had become the top 11th "remover". Today, there are only 3 humans left that have removed more packages than the auto-decrufter... impressively enough, one of them is not even an active FTP-master (anymore). The current score board:
5371 Luca Falavigna 5121 Alexander Reichle-Schmehl 4401 Ansgar Burchardt 3928 DAK's auto-decrufter 3257 Scott Kitterman 2225 Joerg Jaspert 1983 James Troup 1793 Torsten Werner 1025 Jeroen van Wolffelaar 763 Ryan Murray
For comparison, here is the number removals by year for the past 6 years:
5103 2011 2765 2012 3342 2013 3394 2014 3766 2015 (1842 removed by auto-decrufter) 2845 2016 (2086 removed by auto-decrufter)
Which tells us that in 2015, the FTP masters and the decrufter performed on average over 10 removals a day. And by the looks of it, 2016 will surpass that. Of course, the auto-decrufter has a tendency to increase the number of removed items since it is an advocate of "remove early, remove often!". :)
---
Data is from https://ftp-master.debian.org/removals-full.txt. Scoreboard computed as:
grep ftpmaster: removals-full.txt | \ perl -pe 's/.*ftpmaster:\s+//; s/\]$//;' | \ sort | uniq -c | sort --numeric --reverse | head -n10
Removals by year computed as:
grep ftpmaster: removals-full.txt | \
perl -pe 's/.* (\d{4}) \d{2}:\d{2}:\d{2}.*/$1/' | uniq -c | tail -n6
(yes, both could be done with fewer commands)
Lintian 2.5.44 was released the other day and (to most) the most significant bug fix was probably that Lintian learned about Policy 3.9.8. I would like to thank Axel Beckert for doing that. Notably it also made me update the test suite so to make future policy releases less painful.
For others, it might be the fact that Lintian now accepts (valid) versioned provides (which seemed prudent now that Britney accepts them as well). Newcomers might appreciate that we are giving a much more sensible warning when they have extra spaces in their changelog "sign off" line (rather than pretending it is an improper NMU). But I digress...
What I am here to talk about is that Lintian 2.5.44 started classifying packages based on various "facts" or "properties", we can determine. Therefore:
- Every package will have at least one tag now!
- These labels are known as something called "classification tags".
- The tags are not issues to be fixed! (I will repeat this later to ensure you get this point!)
Here are some of the "labelled boxes" your packages will be put into[0]:
- Source packages will unconditionally have both:
- Binary packages will have one of:
The tags themselves are (as mentioned) mere classifications and their primary purpose is to classify or measure certain properties. With them any body can download the data set and come with some bold statement about Debian packages (hopefully without relying too much on "lies, damned lies and statistics"). Lets try that immediately!
- Almost 75% of all Debian packages do not need to run arbitrary code doing installation[2]!
- The "dh-sequencer" with cdbs is the future![3]
In the next release, we will also add tracking of auto-generated snippets from dh_*-tools. Currently unversioned, but I hope to add versioning to that so we can find and rebuild packages that have been built with buggy autoscripts (like #788098)
If you want to see the classification tags for your package, please run lintian with like this:
# Add classification tags $ lintian -L +classification <pkg-or-changes> # Or if you want only classification tags$ lintian -L =classification <pkg-or-changes>
Please keep in mind that classification tags ("C") are not issues in themselves. Lintian is simply attempting to add a visible indicator about a given "fact" or "property" in the package - nothing more, nothing less.
Future work - help (read: patches) welcome:
- Do something better with classification tags on lintian.d.o (like stacked graphs)
- Classify more (useful) things.
- Optimising the memory usage of the reporting framework now that we permanently increased the number of tags.
- Your idea (with patches) here ...
---
[0] Mind you, the reporting framework's handling of these tags could certainly be improved.
[1] Please note how it distinguishes 1.0 into native and non-native based on whether the package has a diff.gz. Presumably that can be exploited somehow ...
[2] Disclaimer: At the time of writing, only ~80% of the archive have been processed. This is computed as: NS / (NS + WS), where NS and WS are the number of unique packages with the tags "no-ctrl-scripts" and "ctrl-script" respectively.
[3] ... or maybe not, but we got two packages classified as using both CDBS and the dh-sequencer. I have not looked at it in detail. For the curious: libmecab-java and ctioga2.
I decided to take a couple of days of vacation next to Easter and obviously ended up with tons of time. I ended up channelling most of the (productive) time into improving Britney.
In raw results:
- I wrote about 35 patches during my (extended) Easter holiday + reviewed and merged/cherry-picked 2 patches from others.
- Today, the "britney-fixes-2016-03" branch had 48 commits not yet in master (8 or so written before Easter).
- I submitted 33 of the patches for review with the intention of merging them into master soon.
- The rest will be bundled for a later round.
The most "exciting" items in the patch series are probably:
- Support for versioned provides (#786803)
- Admittedly, there is a complete punt on multi-arch'ified provides.
- Avoid cruft re-entering testing to satisfy dependencies of other packages
- First step towards supporting packages being read from a standard (dak-built) mirror.
- Britney still assumes some data files are stored in the "mirror". Though it will hopefully work for derivatives/users that disables (read: patches out) the aging and RC bugs policies.
- Future work include"partial" suite support and self-contained components.
- A crash fix (#815995) that only occurs with package "hijacking" (i.e. multiple source packages building the same binary).
Once reviewed, these will be merged into master and we will have versioned provides support (in Britney). :)
About 7 months ago, I wrote about we had improved Lintian's performance. In 2.5.41, we are doing another memory reduction, where we primarily reduce the memory consumption of data about ELF binaries. Like previously, memory reductions follows the "less is more" pattern.
My initial test subject was linux-image-4.4.0-trunk-rt-686-pae_4.4-1~exp1_i386.deb. It had a somewhat unique property that the ELF data made up a little over half the cache.
- We do away with a lot of unnecessary default values [f4c57bb, 470875f]
- That removed about ~3MB (out of 10.56MB) of that ELF data cache
- Discard section information we do not use [3fd98d9]
- This reduced the ELF data cache to 2MB (down from the 7MB).
- Then we stop caching the output of file(1) twice [7c2bee4]
- While a fairly modest reduction (only 0.80MB out of 16MB total), it also affects packages without ELF binaries.
At this point, we had reduced the total memory usage from 18.35MB to 8.92MB (the ELF data going from 10.56MB to 1.98MB)[1]. At this point, I figured that I was happy with the improvement and discarded my test subject.
While impressive, the test subject was unsurprisingly a special case. The improvement in "regular" packages[2] (with ELF binaries) were closer to 8% in total. Not being satisfied with that, I pulled one more trick.
- Keep only "UND" and ".text" symbols [2b21621]
- This brought coreutils (just the lone deb) another 10% memory reduction in total.
In the grand total, coreutils 8.24-1 amd64 went from 4.09MB to 3.48MB. The ELF data cache went from 3.38MB to 2.84MB. Similarly, libreoffice/4.2.5-1 (including its ~170 binaries) has also seen a 8.5% reduction in total cache size[3] and is now down to 260.48MB (from 284.83MB).
--
[1] If you are wondering why I in 3fd98d9 wrote "The total "cache" memory usage is approaching 1/3 of the original for that package", then you are not alone. I am not sure myself any more, but it seems obviously wrong.
[2] FTR: The sample size of "regular packages" is 2 in this case. Of which one of them being coreutils...
[3] Admittedly, since "take 2" and not since 2.5.40.2 like the rest.
You have probably tried to run lintian (-EIL +pedantic) on your packages only to watch lintian drown your terminal. If you have, you would certainly not be the first.
A concrete example with lintian 2.5.40.2:
$ lintian -EIL +pedantic 389-ds-base_1.3.4.5-2_amd64.deb | wc -l 85
Notably, at least 45 of these appeared in 2.5.40 (the hardening-no-bindnow tag):
$ lintian -EIL +pedantic 389-ds-base_1.3.4.5-2_amd64.deb \ --tags hardening-no-bindnow | wc -l 45
In a single release, we have over doubled the number of tags in the given package. I very much doubt this is the first time such a thing happened. Therefore, we have implemented a "per package" tag filter in 2.5.40.
The filter is applied automatically when stdout is a tty and restricts lintian to emitting no more than 3 concrete instances of a given tag per package. If a fourth tag would have been emitted, the filter replaces it with a "how to see all instances" message and suppresses further instances in that package.
Accordingly, lintian "only" emits 25 lines (instead of 85) for the example package. It looks something like this:
$ lintian -EIL +pedantic 389-ds-base_1.3.4.5-2_amd64.deb I: 389-ds-base: spelling-error-in-binary usr/bin/dbscan-bin conents contents X: 389-ds-base: hardening-no-bindnow usr/bin/dbscan-bin X: 389-ds-base: hardening-no-bindnow usr/bin/dsktune-bin X: 389-ds-base: hardening-no-bindnow usr/bin/infadd-bin X: 389-ds-base: hardening-no-bindnow ... use --no-tag-display-limit to see all (or pipe to a file/program) I: 389-ds-base: spelling-error-in-binary usr/lib/x86_64-linux-gnu/dirsrv/libns-dshttpd.so.0.0.0 occured occurred [...]
With this very simple filter in place, the entire lintian output for that single binary now fits on my screen. I am pretty sure the filter could do with additional smarts, but I believe it is a good start.
As I posted earlier, I have migrated to use tor on my machine. Though I had a couple of unsolved issues back then. One of them being my Mail Transport Agent (MTA) did not support tor.
A regular user might not have a lot of use for a MTA on their laptop. However, it is needed for a lot of Debian development scripts (bts, mass-bug, nmudiff), if they are to file/manipulate bugs for you.
I have some requirements for my MTA
- tor support (or at least "torsocks"-able)
- support end-to-end encryption with my provider (STARTTLS)
- verify that it is talking to my provider.
- rewrite my "From" if it is not correct (otherwise the mail will just be rejected)
- support the auth mechanisms of my provider
- it should be simple to configure
I also have some non-requirements:
- Local mail delivery is not required
- The MTA will not be used as a general mail relay.
- One target relay
- No relaying from other hosts
- Mail delivery queue is nice to have but not a strict requirement.
Originally, I used postfix, which supported most of these requirements. Except:
- My attempt to make it use tor failed. The best suggestion I found was to divert its smtp handler and then replace it with a torsocks call to the original handler. Sadly, it just seg. faulted.
- While postfix is almost certainly able to verify it is talking with my provider, I never got it configured to do that. In the end, postfix was to complicated for what I was ready to put up with.
Per suggestion of Jakub Wilk, I tried msmtp, which turned out do what I wanted.
- There is a trivial config file example to start with. I did not need to read any manuals or extended documentation to figure out what they were doing.
- You probably also want to specify tls_priorities (assuming msmtp is linked against gnutls)
- A code dive suggests it defaults to "NORMAL:-VERS-SSL3.0" if not set. It is probably not too bad, but could be better. :)
- From a quick look at the gnutls manual "PFS:%PROFILE_<name>" seems like decent value (requires gnutls >= 3.2.4 and that your provider has decent/modern SSL setup).
- You probably want to have a look at the values for the %PROFILE_<name> before deciding on one.
- The msmtp program supports connecting through SOCKS proxies and even has a sample config snippet for using it with tor.
- Of course, by the time I had discovered that I had already been using "torsocks /usr/sbin/sendmail" a couple of times. :)
The only feature I will probably miss is having a local queue, which can be rate limited. But all in all, I am quite happy with it so far. :)
Lucas Nussbaum recently did a blog post called "Debian is still changing". I found it a very welcome continuation of his previous blog post on the same topic. I find the graphs very interesting and was very happy to learn that he included relative graphs this time.
Now I can with relatively ease say that 69% of all Debian packages are using a dh-style build (source). We have another 15% using classic debhelper, which means that at least 84% of all packages uses debhelper directly. Assuming all CDBS based packages rely on the "debhelper class", we are at 99%! The latter is certainly an assumption, although I suspect it is probably pretty accurate[1].
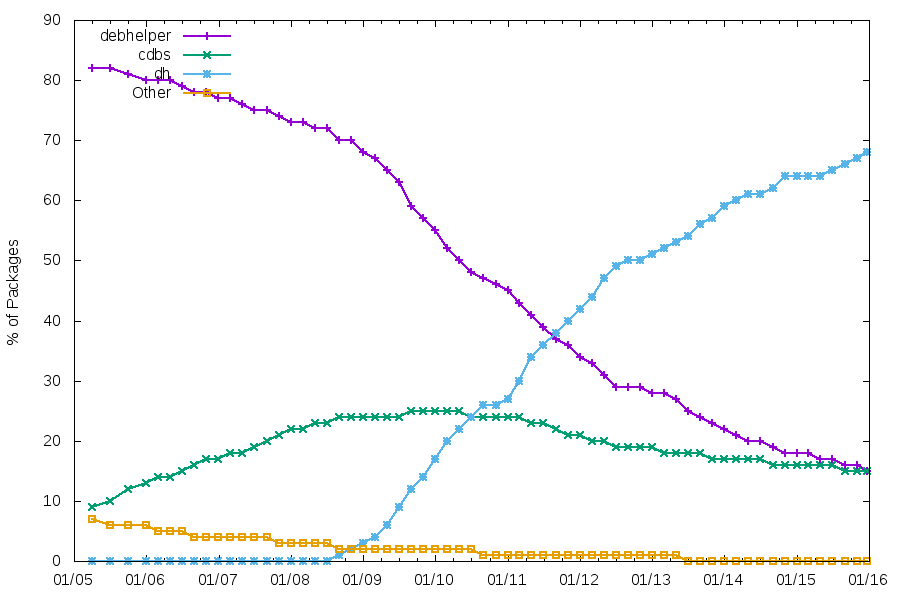{kind=link}
Now, it is very cute to have "world dominance", but that is not my primary interest in these numbers. Instead, we can use these numbers to determine that:
- We can deploy changes to up to 99% of all source packages via existing debhelper tools
- We can deploy changes to up to 84% of all sources packages via debhelper + CDBS if it requires a new debhelper tool.
Such as automatic dbgsym packages, indexable build-id from dbg(sym) packages via Packages files[2], and replacing maintscripts with ldconfig triggers. All of these changes happen to be changes that could be trivially deployed with very little risk and very high efficiency[3]. Notably, none of them required a compat bump (or a new debhelper tool).
Of course, I do not intend to say that every change can (or should) be deployed via debhelper and much less into an existing "dh_cmd"-tool. Notably, dh_strip is reaching its breaking point for content. And if we were to require a compat bump for your change, we can now at least see the adoption rate via lintian. :)
Nevertheless, it is nice to know that (politics aside) there is some agility in the Debian build system! :)
--
[1] I would very much love to see numbers to (dis)prove my assumption about CDBS + debhelper. In fact, an absolute number of packages not using debhelper (indirectly) in Debian would be very intriguing.
[2] New fields by default end up the Packages file. See e.g. the Packages.xz file on the debug mirror or your apt-cache via:
apt-cache show mscgen-dbgsym | grep ^Build-Ids
The latter assumes that you have the debug mirror in your sources list.
[3] Efficiency here being features people rarely override/disable.
In the 4th quarter of 2016, we will freeze Debian Stretch. If you are hoping to do any larger changes for Stretch, please consider starting on them now. This also includes features that need to be in APT/dpkg (etc.) in Stretch, so we can start using them for Buster.
Even something as "trivial" as the automatic dbgsym packages took over 8 months to "complete" (from the prototype was announced in April). I call it "trivial" because:
- The specs were simple and were fairly easy to implement
- Not to mention, the basic idea was already implemented before in e.g. Ubuntu (albeit differently).
- The chosen implementation only had 3 primary tools affected that truly blocked deploying dbgsym packages in Debian.
- dak
- debhelper
- dpkg
- I have yet to hear anyone being against the idea itself.
- There were some concerns about various implementation details. Fortunately almost all of them had trivial or "obvious" solutions.
- We could deploy dbgsym packages immediately once the primary tools had been patched in/for unstable.
- Compared to Multi-Arch, Build-Profiles etc., where we had to wait till the next release before using the feature.
- It also meant we could immediately test that the feature worked as intended (rather than discovering bugs post release).
NB: There were certainly other parties involved. But these were the most important ones.
Mind you, the dbgsym saga is not complete yet. We are still lacking support for migrating dbgsym packages to testing (and, by extension, the next stable release as well). Meanwhile, you can pull the dbgsym packages from snapshot.debian.org.
In summary: If you want a larger change to land in Debian Stretch, please start already now. :)
I have been fiddling with setting up both iptables and tor on my local machine. Most of it was fairly easy to do, once I dedicated the time to actually do it. Configuring both "at the same time" also made things easier for me, but YMMV. Regardless, it did take quite a while researching, tweaking and testing - most of that time was spent on the iptables front for me.
I ended up doing this incrementally. The major 5 steps I went through were:
- Created a basic incoming (INPUT) firewall - enforcing
- Installed tor + torsocks and aliased a few commands to run with torsocks
- Created a basic outgoing (OUTPUT) firewall - permissive
- Make the outgoing firewall enforcing
- Migrate the majority of programs and services to use tor.
Some of these overlapped time-wise and I certainly revisited the configuration a couple of times. A couple of things, that I learned:
- You probably want to have a look at "netstat --listen -put --numeric" when you write your INPUT firewall.
- The tor developers have tried a lot to make things easy. It is scary how often "torsocks program [args]" just works(tm).
- That said, it does not always work.
- Tor and iptables (OUTPUT) can have a synergy effect on each other.
- Notably, when it is easier to just "torsocks" a program than adding the necessary iptables rules.
- Writing iptables rules become a lot easier once:
- You learn how to iptables's LOG rule
- You use sensible-editor + iptables-restore or something like puppet's firewall module
After 3 months of installing an automatic decrufter in DAK, it:
- has removed 689 cruft items from unstable and experimental
- average removal rate being just shy of 230 cruft items/month
- has become the "top 11th remover".
- is expected to become top 10 in 6 days from now and top 9 in 10 days.
- This is assuming a continued average removal rate of 7.6 cruft items per day
On a related note, the FTP masters have removed 28861 items between 2001 and now. The average being 2061 items a year (not accounting for the current year still being open). Though, intriguingly, in 2013 and 2014 the FTP masters removed 3394 and 3342 items. With the (albeit limited) stats from the auto-decrufter, we can estimate that about 2700 of those were cruft items.
One could certainly also check the removal messages and check for the common "tags" used in cruft removals. I leave that as an exercise to the curious readers, who are not satisfied with my estimate. :)
Thanks to hard work of Adam, Julien, Jonathan, Matthias, Scott, Simon and many others, the GCC-5/libstdc++ transition has progressed to a state, where we are ready to migrate the bulk of it to testing.
It should be a mostly smooth ride. However, there will a few packages that are going to be uninstallable in testing for a few days and some packages will be temporarily removed from testing. If APT is unable to provide you with an upgrade for all of your packages, please try again in a few days. We apologise for the inconvenience.
Currently, we expect about 36 binary packages to become temporarily uninstallable on amd64 and 34 on i386. This involves Britney accepting at least 4800 "change items" on testing (some of these are removals). Many thanks to Julien for providing a proposed set of hints and Adam extending them.
Update: We now got a list of the packages being removed and a list of packages becoming uninstallable. It will be available on debian-devel within 20 minutes from now.
So, yesterday, I "unbroke" dak - twice even! It is of course slightly less awesome that one of the broken parts was in code written by yours truly. Anyhow:
Unbreaking the dak auto-decrufter
You may remember the auto-decrufter, which I added to dak. As a safety measure, it bails out when in doubt about which removal breaks what package. Turns out it was often in doubt, because the code had a bug. Of course, nothing that could not be solved with a patch.
Thanks to Ansgar for merging this. :)
Unbreaking dak generate-releases
As a part of migrating apt-file to use APTs new acquire system (from experimental), I learned APT really likes having checksums for everything. Now including checksums for both the compressed file and the uncompressed file.
Sadly, dak had optimised out the uncompressed checksums for Contents files, but even after removing that optimisation (and Ganneff unbreaking my dinstall breakage) some Contents files still did not have an checksum for the uncompressed Contents file. After some sophisticated debugging (read: "printf-debugging"), I finally discovered the issue and submitted a patch.
Thanks to Ansgar and Ganneff for merging (and fixing my dinstall breakage).
The other day, I wrote about our recent performance tuning in lintian. Among other things, we reduced the memory usage by ~33%. The effect was also reproducible on libreoffice (4.2.5-1 plus its 170-ish binaries, arch amd64), which started at ~515 MB and was reduced to ~342 MB. So this is pretty great in its own right...
But at this point, I have seen what was in "Pandora's box". By which, I mean the two magical numbers 1.7kB per file and 2.2kB per directory in the package (add +250-300 bytes per entry in binary packages). This is before even looking at data from file(1), readelf, etc. Just the raw index of the package.
Depending on your point of view, 1.7-2.2kB might not sound like a lot. But for the lintian source with ~1 500 directories and ~3 300 non-directories, this sums up to about 6.57MB out of the (then) usage at 12.53MB. With the recent changes, it dropped to about 1.05kB for files and 1.5kB for dirs. But even then, the index is still 4.92MB (out of 8.48MB).
This begs the question, what do you get for 1.05kB in perl? The following is a dump of the fields and their size in perl for a given entry:
lintian/vendors/ubuntu/main/data/changes-file/known-dists: 1077.00 B _path_info: 24.00 B date: 44.00 B group: 42.00 B name: 123.00 B owner: 42.00 B parent_dir: 24.00 B size: 42.00 B time: 42.00 B (overhead): 694.00 B
With time, date, owner and group being fixed sized strings (at most 15 characters). The size and _path_info fields being integers, parent_dir a reference (nulled). Finally, the name being a variable length string. Summed the values take less than half of the total object size. The remainder of ~700 bytes is just "overhead".
Time for another clean up:
- The ownership fields are usually always "root/root" (0/0). So let's just omit them when they satisfy said assumption. [f627ef8]
- This is especially true for source packages where lintian ignores the actual value and just uses "root/root".
- The Lintian::Path API has always had a "cop-out" on the size field for non-files and it happens to be 0 for these. Let's omit the field if the value was zero and save 0.17MB on lintian. [5cd2c2b]
- Bonus: Turns out we can save 18 bytes per non-zero "size" by insisting on the value being an int.
- Unsurprisingly, the date and time fields can trivially be merged into one. In fact, that makes "time" redundant as nothing outside Lintian::Path used its value. So say goodbye to "time" and good day to 0.36MB more memory. [f1a7826]
Which leaves us now with:
lintian/vendors/ubuntu/main/data/changes-file/known-dists: 698.00 B _path_info: 24.00 B date_time: 56.00 B name: 123.00 B parent_dir: 24.00 B size: 24.00 B (overhead): 447.00 B
Still a ~64% overhead, but at least we reduced the total size by 380 bytes (585 bytes for entries in binary packages). With these changes, the memory used for the lintian source index is now down to 3.62MB. This brings the total usage down to 7.01MB, which is a reduction to 56% of the original usage (a.k.a. "the-almost-but-not-quite-50%-reduction").
But at least the results also carried over to libreoffice, which is now down to 284.83 MB (55% of original). The chromium-browser (source-only, version 32.0.1700.123-2) is down to 111.22MB from 179.44MB (61% of original, better results expected if processed with binaries).
In closing, Lintian 2.5.34 will use slightly less memory than 2.5.33.