
Ganeti Playbook
How to use your cluster
- Guido Trotter <ultrotter@google.com>
- Helga Velroyen <helgav@google.com>
Latest version of these slides
Please find the latest version of these slides at:
Outline
- Adding nodes
- Organizing nodes
- Repairs
- Ganeti upgrades
Adding nodes
- Install and configure the node
- or let your configuration management do the job
- Add the node with
gnt-node add <name>- (asks for root passwords if key authentication is not possible)
Organizing nodes
- In a big cluster you want to organize nodes into groups.
- Ganeti will make sure instances' primary and secondary nodes are in the same group.
- Rule of thumb: One group per subnet
- Other possible considerations:
- physical location (rack)
- homogeneous architecture
- homogenous hypervisor
# gnt-group add group2 # gnt-group rename default group1 # gnt-group assign-nodes group2 node20 node21 node22 ... # gnt-instance change-group --to group1 instance_name
Recovering from master failure
# on a master candidate gnt-cluster master-failover # use --no-voting on a 2 node cluster
(A linux-HA experimental integration is present in 2.7)
Preemptively evacuating a node
We can remove instances from a node when we want to perform some maintenance.
Drain, move instances, check, set off-line:
gnt-node modify -D yes node2 # mark as "drained" gnt-node migrate node2 # migrate instances gnt-node evacuate node2 # remove DRBD secondaries gnt-node info node2 # check your work gnt-node modify -O yes node2 # mark as "offline"
It is now safe to power off node2
Recovering from node failure (1)
Offlining the node
Set the node offline:
gnt-node modify -O yes node3
Use --auto-promote or manually promote a node if the node was a master candidate.
(This step can also be automated using linux-HA)
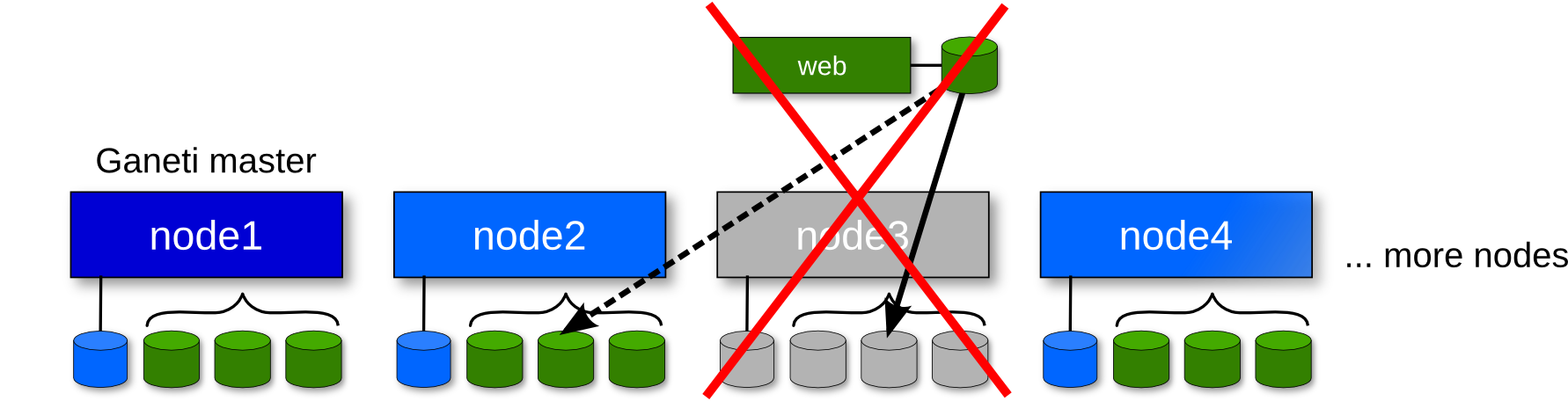
Recovering from node failure (2)
Failover the instances' secondaries
gnt-node failover --ignore-consistency node3
or, for each instance:
gnt-instance failover --ignore-consistency web
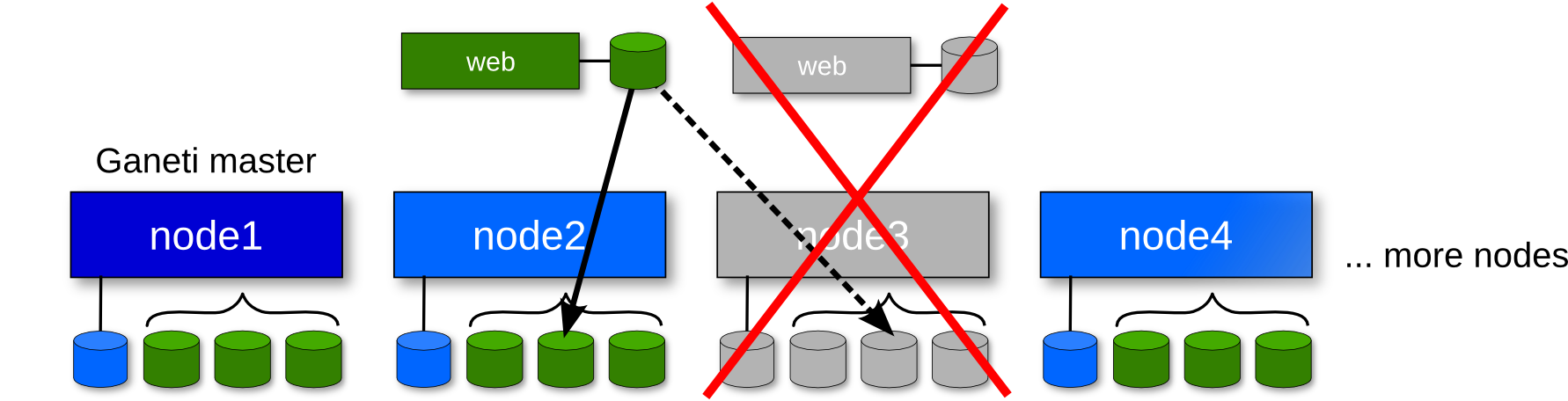
Recovering from node failure (3)
Restoring redundancy
gnt-node evacuate -I hail node3
or, for each instance:
gnt-instance replace-disks {-n node1 | -I hail } web
(The autorepair tool in Ganeti 2.7 can automate these two steps)
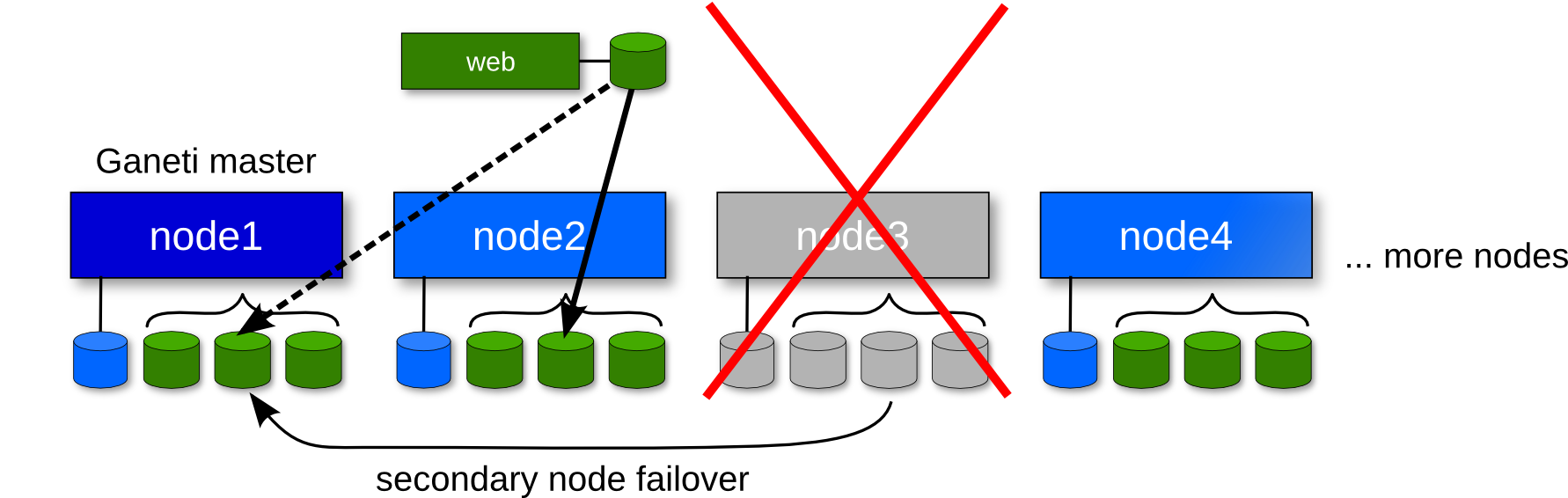
Re-add an off-lined node
After a node comes back:
gnt-node add --readd node3
Then it's a good idea to rebalance the cluster:
hbal -L -X
Maintenance
Shutting/Starting down all instances:
gnt-instance stop|start --all [--no-remember]
Blocking/Unblocking jobs:
gnt-cluster queue [un]drain
Stopping the watcher:
gnt-cluster watcher pause <timespec>|continue
Cluster Shutdown
Graceful shutdown before powering off nodes:
gnt-cluster verify gnt-cluster watcher pause 6000 gnt-instance stop --all --no-remember gnt-cluster queue drain gnt-job list --running # Check if jobs have completed
Emergency shutdown (faster):
gnt-instance stop --all --no-remember
Cluster Re-start
After a graceful shutdown, return the cluster to service:
gnt-cluster queue undrain gnt-cluster watcher continue
The watcher will restart all instances in 10-20 minutes:
gnt-cluster verify
Ganeti upgrades
From the master node:
alias gnt-dsh=dsh -cf /var/lib/ganeti/ssconf_online_nodes
Stop Ganeti:
gnt-dsh /etc/init.d/ganeti stop
Now unpack/upgrade the new version on all nodes. eg:
gnt-dsh apt-get install ganeti2=2.7.1-1 ganeti-htools=2.7.1-1
Now upgrade the config and restart
/usr/lib/ganeti/tools/cfgupgrade gnt-dsh /etc/init.d/ganeti start gnt-cluster redist-conf
Further information and outlook
Regarding upgrades, we are currently (as of 2.10) working on upgrading Ganeti from inside Ganeti, to make upgrading smoother.
For more best practices, see the Ganeti administrator's guide
Thank You!
Questions?
Survey at https://www.usenix.org/lisa13/training/survey
- © 2010 - 2013 Google
- Use under GPLv2+ or CC-by-SA
- Some images borrowed / modified from Lance Albertson and Iustin Pop
- Some slides were borrowed / modified from Tom Limoncelli
